Matillion Data Productivity Cloud (DPC) has been quick to integrate some great AI features. AI helps with accelerating data engineering processes and can automate tasks which previously required laborious human effort. One of the use cases where leveraging AI can be beneficial is in the enrichment of data with metadata. In this blog post, Erick Ferreira illustrates this by enriching the publicly available IMDb dataset (see reference below). The enrichment is done with Cortex, which is Snowflake’s managed AI and machine learning service, and Matillion’s DPC, for fast and reliable engineering of data pipelines.
About the IMDb Dataset
IMDb provides an online database containing information about films and other sorts of digital content, such as television shows, video games and streaming content. The database was launched 34 years ago as a fan-operated movie database and nowadays, it is owned and operated by IMDb.com, Inc, a subsidiary of Amazon. The non commercial datasets can be used free of charge for non-commercial purposes1).
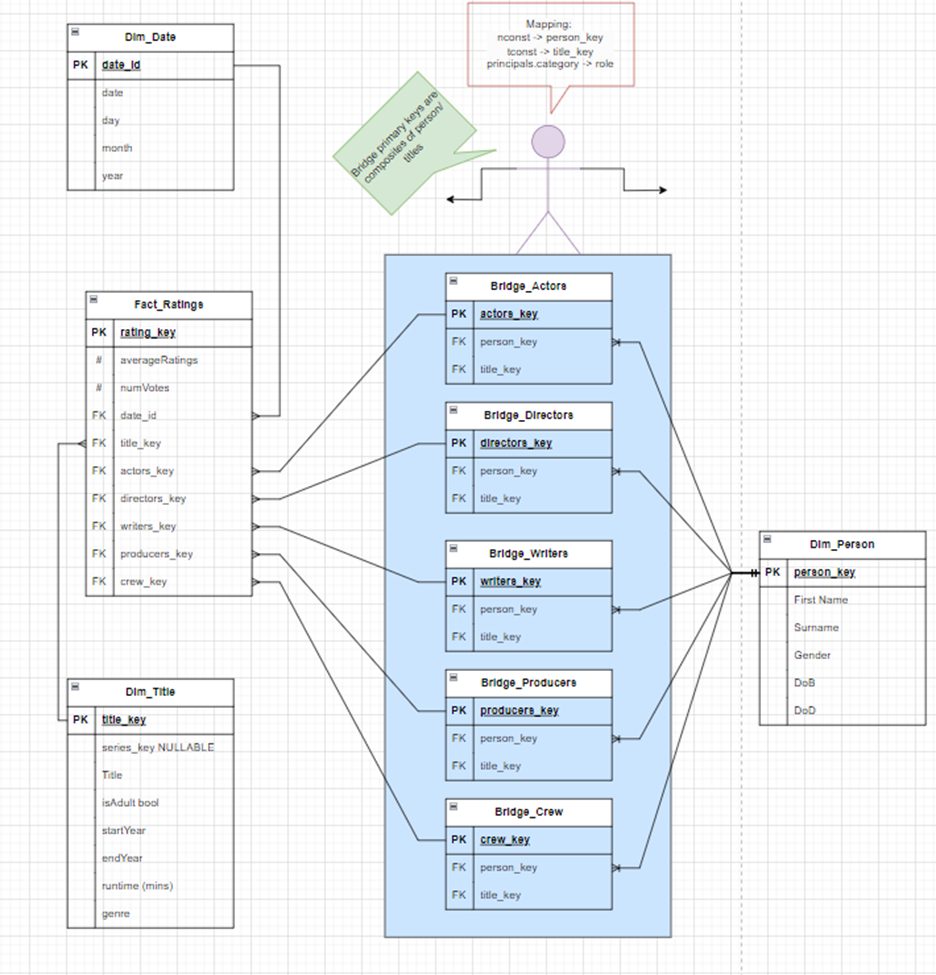
At Snap Analytics, we use the IMDb dataset for training purposes. Snap’s dimensional model (pictured on this page) for the IMDb database gives us a good starting point for metadata enrichment with AI. Here is the simplified model:
On top of this dimensional model, we added a reporting table with consolidated information about films, such as the name of the film, year of release, the director’s name, a summary of the film, duration, genre, etc…
IMDb data model
The challenge
We have the following two requirements for our use case:
- We would like to know which film directos might have German ancestors. This information is not available in the metadata. We will use Cortex AI Completion to analyse the directors names, and add a column with an indication whether the name has a German origin or not.
- For the Spanish speaking users, we would like to add a translation of the English film summary into Spanish. We will use Cortex Translate to automatically create this translation.
Below are the steps to achieve both requirements, by creating a DPC pipeline with some out of the box components.
Step 1: Create a Transformation Pipeline
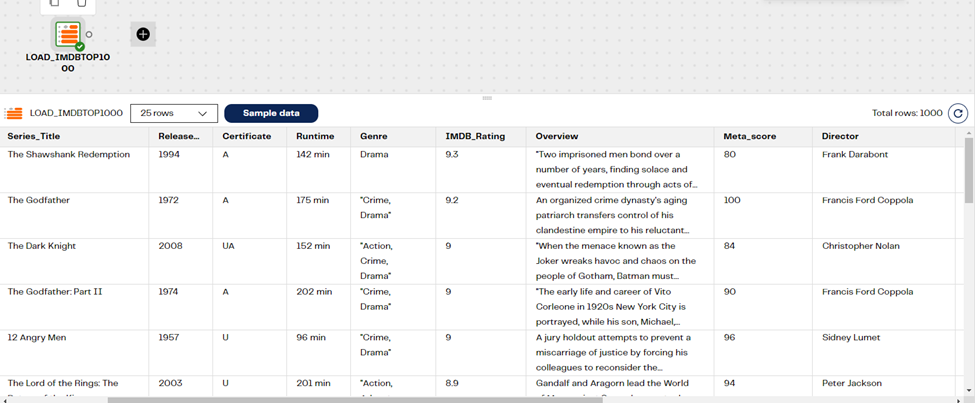
First, we created a Transformation pipeline with an Input Table component pointing to the IMDb reporting table, have a look at the screenshot below containing a sample of the data.
Step 2: Getting Directors with German Ancestors
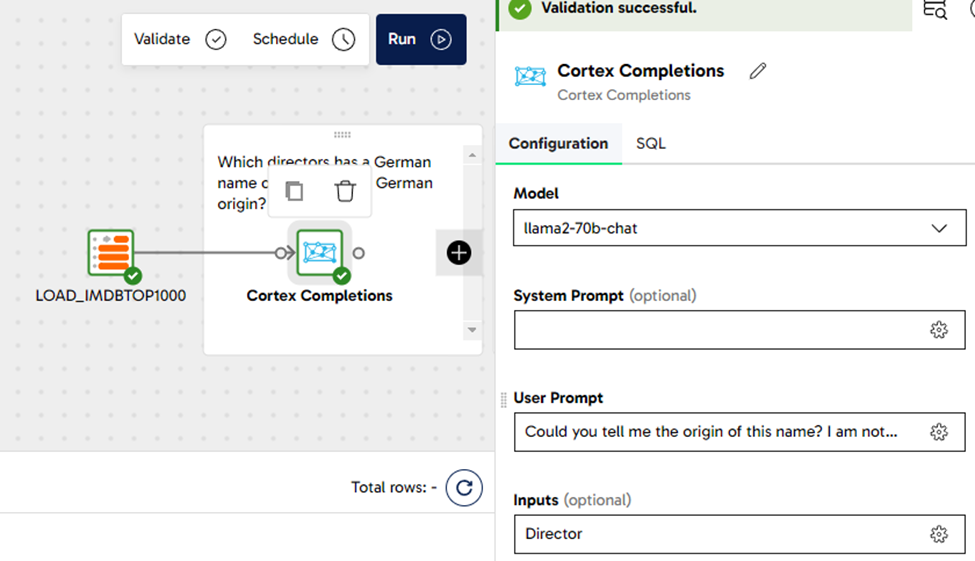
From the reporting table, we would like to recommend the films from German directors. We have used the Cortex Completions component using the Model llama-70b-chat with the following user prompt: Could you tell me the origin of this name? I am not interested in the nationality of the director; I would like to know the background of the name. We applied the question against the Director column. This will try to find all the surnames which have a German background.
Look at the image below for some reference about the settings and how the pipeline looks like:
After doing a sample over the Cortex Completions component, we can see the “completion_result” column in JSON format with the answer in the “messages” attribute containing the origin of the director’s name.
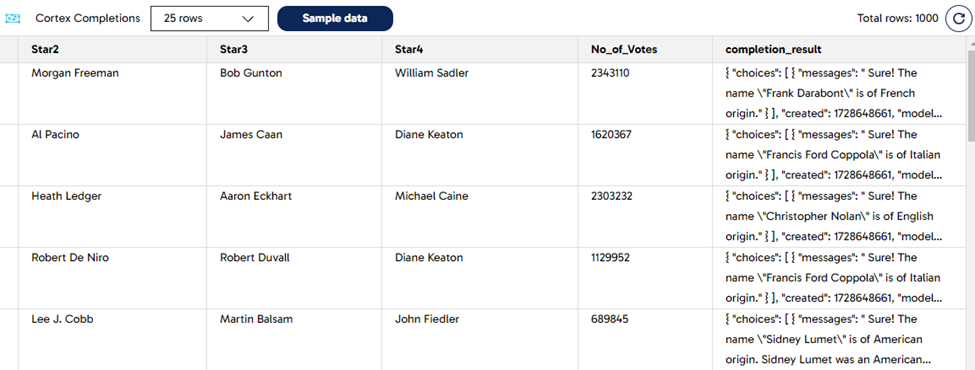
This simple action of getting the background of a surname would have been a very laborious task without leveraging the use of Large Language Models (LLM). Moreover, it may require some extensive research, and potentially integrating with a third-party tool.
Step 3: Translate the Film Summary to Spanish
We use the Cortex Translate component in DPC to generate a Spanish translation. The “Overview” column contains the English original summary, which is used as input. Look at the example below for the settings and the outcome after sampling the data:
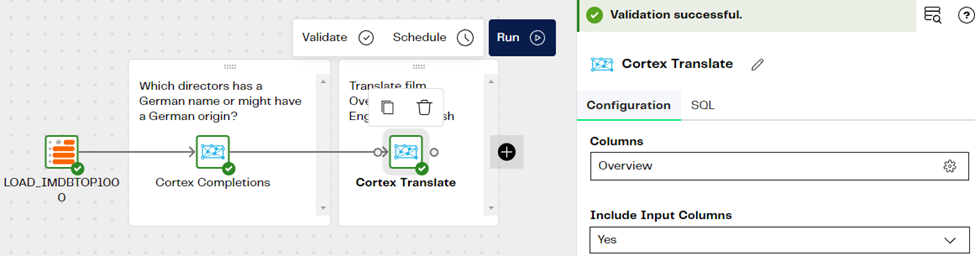
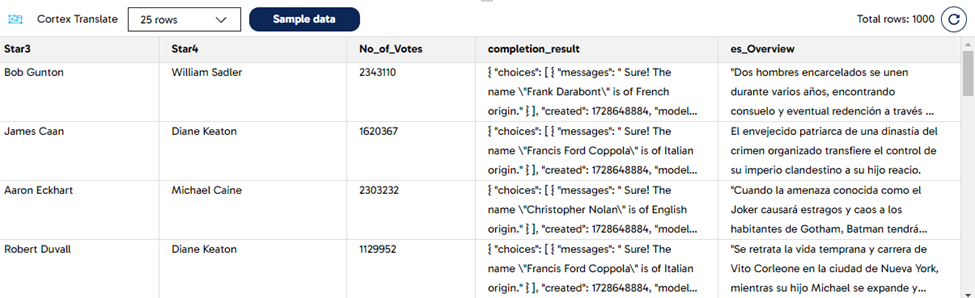
The Cortex Translate component will not only let you to translate from English to Spanish. There are several languages which you can select from the drop-down menu of the component. You can even have multiple columns as part of the output, one for each language that you need.
Step 4: Extract from semi-structured data
Now, as we are working in a Transformation pipeline and the outcome for the director’s surname is in JSON format, we can extract the “messages” attribute and then filter it out later in our pipeline. To do this, we can use the Extract Nested Data component. We will only check the messages field after autofilling the columns, this will allow us to get a new column with just the value for the “messages” attribute in plain text. Look at this below:
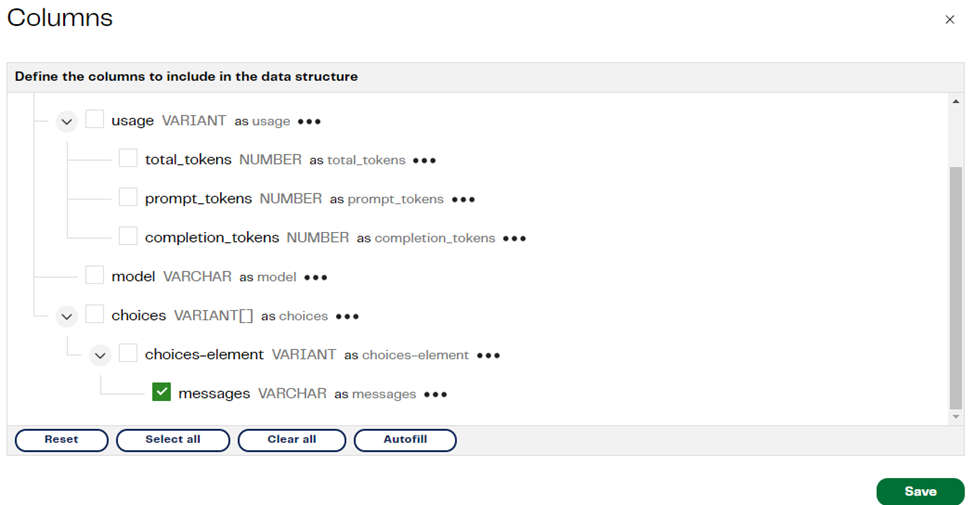
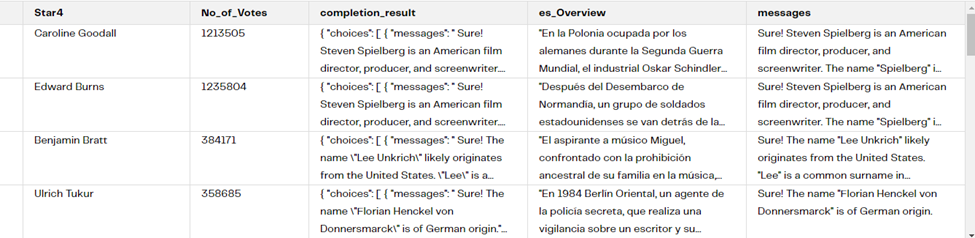
Step 5: Filtering the data
As we mentioned earlier, we want to only get the films for directors with German surnames, so we can use the Filter component to get only the rows where the text “Germany” or “German” appears. Check the filter condition property on the screenshot below:
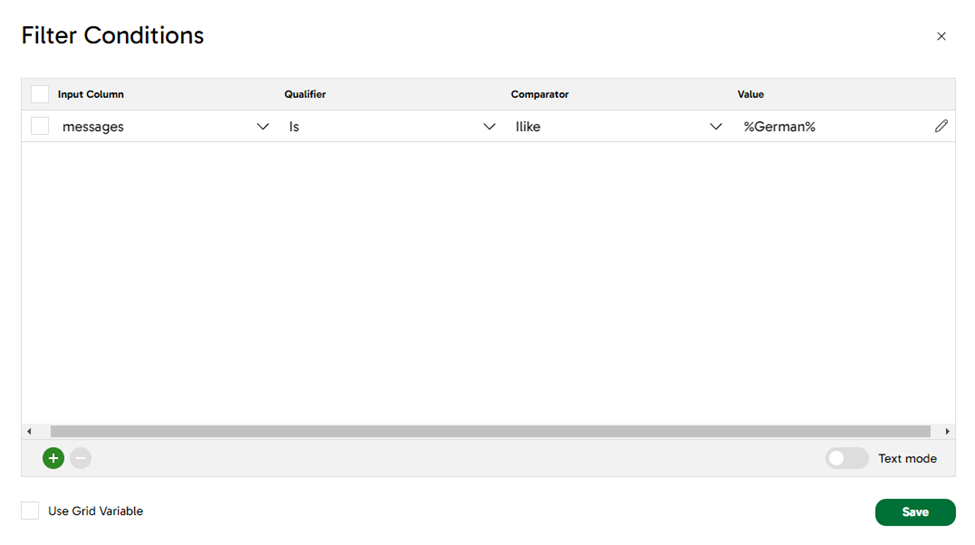
This simple step will help us to remove all the rows in which the LLM did not identify a surname with a German background.
Step 6: Create a new table in Snowflake
Finally, we just must write the outcome of our pipeline into a table, we can use the Rewrite Table component to achieve this very easily. We will call our table “german_directed_films”. After running the pipeline, we should have a new table in Snowflake showing the specific outcome we built.
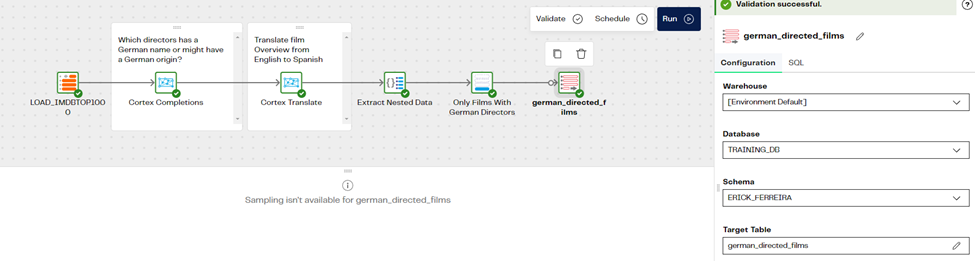
Step 7: The results
From the original reporting table containing 1,000 rows, we now have a smaller table containing only 100 rows. Each row represents a film with a director who has a German surname. Also, we have an extra column with the overview of the film in Spanish. Have a quick look at a sample of the data with the three new columns we created while building our pipeline:
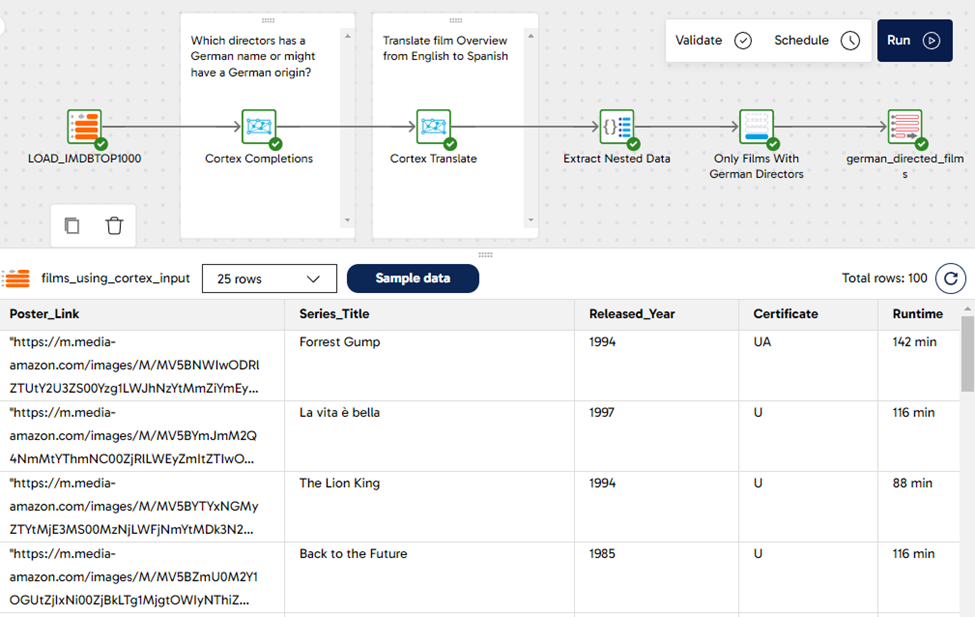
Final thoughts
The new Snowflake Cortex is a game changer for analytics projects, it has the capacity to enhance metadata as we have demonstrated, and it is easy to see the value for more complex use cases, such as incorporating sentiment analysis or performing in-depth document analysis to generate outcomes that can be joined with more traditional business metrics.
Even though DPC is a platform mainly built for data engineering, you can see how easy it is to leverage the new AI features offered by Snowflake with a full no-code approach. DPC also brings other out of the box Orchestration components that leverage Large Language Models that we are also planning to cover as part of the other posts, such as vector databases and embeddings.
If you are looking to build data pipelines quickly and combine your analytics project with new AI features, DPC is definitely a platform you should try out. Here at Snap Analytics, we can also support you with your data and AI projects, especially if you are already a Snowflake user!
References and footnotes
Footnote 1:
The IMDb non-commercial datasets can be used free of charge within the restrictions as set out by the non-commercial licensing agreement and within the limitations specified by copyright / license.
Please refere to this page for more information:
IMDb (2024) IMDb Non-Commercial Datasets. Available at: https://developer.imdb.com/non-commercial-datasets/ (Accessed 16 September 2024)
Useful links:
Snowflake (2024) Snowflake Cortex Functions. Available at: https://docs.snowflake.com/en/user-guide/snowflake-cortex/llm-functions (Accessed 16 September 2024)
Matillion (2024) Cortex Completions. Available at: https://docs.matillion.com/data-productivity-cloud/designer/docs/cortex-completions/ (Accessed 16 September 2024)
Matillion (2024) Cortex Translate. Available at: https://docs.matillion.com/data-productivity-cloud/designer/docs/cortex-translate/ (Accessed 16 September 2024)