In the first three posts of this series, we delved into some necessary details from graph theory, reviewed acyclic graphs (DAGs), and touched on some foundational concepts that help describe what hierarchies are and how they might best be modeled.
In the fourth post of the series, we spent time considering an alternative model for hierarchies: the level hierarchy which motivated several interesting discussion points including:
- The fact that many common fields (and collections of fields) in data models (such as dates, names, phone numbers, addresses and URLs) actually encapsulate level hierarchies.
- A parent-child structure, as simple/robust/scalable as it can be, can nonetheless overcomplicate the modeling of certain types of hierarchies (i.e. time dimensions as a primary example).
- Level hierarchies are also the requisite model for most “modern data stack” architectures (given that a majority of BI tools do not support native SQL-based traversal of parent-child hierarchies).
- As such, parent-child hierarchies are often appropriate for the integration layer of your data architecture, whereas level hierarchies are often ideal for your consumption layer.
- The corresponding “flattening” transformation logic should probably be implemented via recursive CTEs (although other approaches are possible, such as self-joins).
- When/where to model various transformations, i.e. in physical persistence (schema-on-write) or via logical views (schema-on-read), and at what layer of your architecture depends on a number of tradeoffs and should be addressed deliberately with the support of an experienced data architect.
At the very end of the last (fourth) post, we examined an org chart hierarchy that included a node with a rather ambiguous level attribute. The “natural” level differed from the “business” level and thus requires some kind of resolution.
So, let’s pick back up from there.
Introducing Unbalanced & Ragged Hierarchies
Unbalanced Hierarchies
We had a quick glance at this example hierarchy, which is referred to as an unbalanced hierarchy:
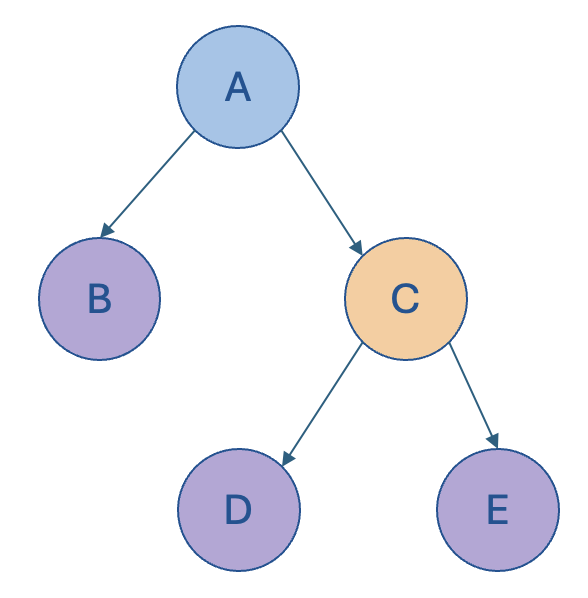
- In this example, node B is clearly a leaf node at level 2, whereas the other leaf nodes are at level 3.
- Stated differently, not all paths (i.e. from the root node to the leaf nodes) extend to the same depth, hence giving this model the description of being “unbalanced”.
As we indicated previously, most joins from fact tables to hierarchies take place at the leaf nodes. Given the unbalanced hierarchies have leaf nodes at different levels, there’s clearly a challenge in how to effectively model joins against fact tables in a way that isn’t unreasonably brittle.
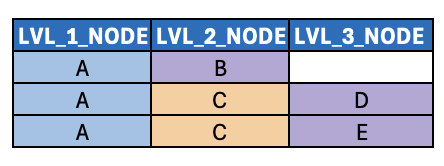
We did solve for this particularly challenge (by introducing a dedicated leaf node column, i.e. LEAF_NODE_ID), but there are more to consider later on.
But let’s next introduce ragged hierarchies.
Ragged Hierarchies
In the last post, we provided a concrete example of this hierarchy as an org chart, demonstrating how node B (which we considered as an Executive Assistant in a sample org chart) could be described as having a “business” level i.e. of 3 that differs from what we’re calling its “natural” level of 2. We’ll refer to such hierarchies as ragged hierarchies.
(For our purposes, we’ll only refer to the abstract version of the hierarchy for the rest of this post, but it’s worth keeping real-world use cases of ragged hierarchies in mind, such as the org chart example.)
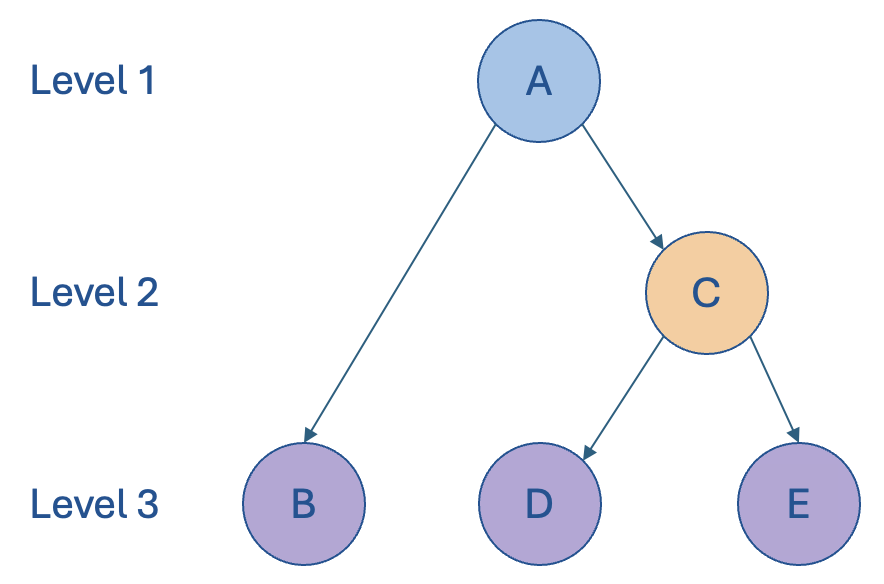
A ragged hierarchy is defined as a hierarchy in which at least one parent node has a child node specified at more than one level away from it. So in the example above, node B is two levels away from its parent A. This also means that ragged hierarchies contain edges that span more than one level (i.e. the edge [A, B] spans 2 levels).
Ragged hierarchies have some interesting properties as you can see. For example:
- Adjacent leaf nodes might not be sibling nodes (as is the case with nodes B and D).
- Sibling nodes can be persisted at different (business) levels, i.e. nodes B and C.
The challenge with ragged hierarchies is trying to meaningfully aggregate metrics along paths that simply don’t have nodes at certain levels.
Having now introduced unbalanced and ragged hierarchies, let’s turn out attention to how to model them in parent-child and level hierarchy structures.
Modeling Unbalanced and Ragged Hierarchies
Modeling Unbalanced Hierarchies (Parent/Child)
A parent/child structure lends itself to directly modeling an unbalanced hierarchy. The LEVEL attribute corresponds directly to the derived value, i.e. the “depth” of a given node from the root node. (It’s also worth noting that B, despite being a leaf node at a different level than other leaf nodes, is still present in the CHILD_NODE column as with all leaf nodes, supporting direct joins to fact tables (and/or “cubes”) in the case of MDX or similar languages).
No specific modifications to either the model or the data are required.
- No modifications need if you’re querying this data with MDX from your consumption layer.
- No modifications needed if you model this data in your integration layer (i.e. in a SQL context).
- But as already discussed, if SQL is your front-end’s query language (most likely), then of course this model won’t serve well in your consumption layer.
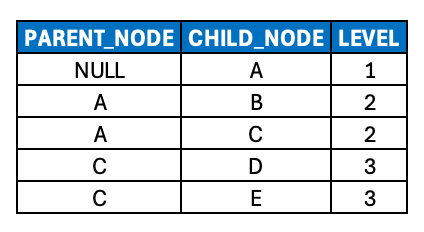
Modeling Unbalanced Hierarchies (Level)
With the assumption previously discussed that any/all related fact tables contain foreign key values only of leaf nodes of a given hierarchy, node B should be extended into the dedicated LEAF_NODE (or LEAF_NODE_ID depending on your naming conventions) column introduced in the last post (along with nodes D and E). Thus, joins to fact tables can take place consistently against a single column, decoupled from the unbalanced hierarchy itself.
The next question, then, becomes – what value should be populated in the LEVEL_3_NODE column?
Generally speaking, it should probably contain NULL or some kind of PLACEHOLDER value. That way, the resulting analytics still show metrics assigned to node B (via the leaf node join), but they don’t roll up to a specific node value at level 3, since none exists. Then at LEVEL_2_NODE aggregations, the analytics clearly show the LEAF_NODE value matching LEVEL_2_NODE.
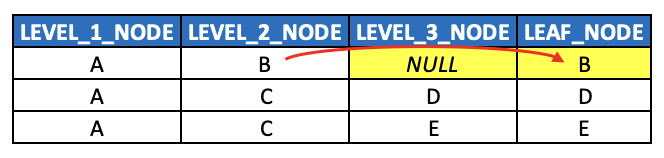
(For illustration purposes, I’m leaving out related columns such as SEQNR columns)
Another option is to also extend the leaf node value, i.e. B, down to the missing level (i.e. LEVEL_3_NODE).
- This approach basically transforms an unbalanced hierarchy into a ragged hierarchy. It’s a less common approach, so it’s not illustrated here.
Modeling Ragged Hierarchies (Parent/Child)
A parent/child structure can reflect a ragged hierarchy by modeling the data in such a way that the consumption layer queries the business level rather than the natural level. The simplest way to do so would be to just modify your data pipeline with hard-coded logic to modify the nodes in question by replacing the natural level with the business level, as visualized here. (Note that this could done physically, i.e. as data is persisted in your pipeline, or logically/virtually in a downstream SQL view.)
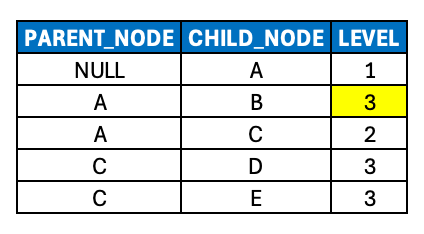
Such an approach might be okay if:
- such edge case (nodes) are rare
- if the hierarchies change infrequently,
- if future changes can be managed in a deliberate fashion,
- and if it’s very unlikely that any other level attributes need to be managed (i.e. more than one such business level)
Otherwise, this model is likely to be brittle and be difficult to maintain, in which case the integration layer model should probably be physically modified to accommodate multiple different levels, and the consumption layer should also be modified (whether physically or logically) to ensure the correct level attribute (whether “natural”, “business” or otherwise) is exposed. This is discussed in more detail below in the section “Versioning Hierarchies”.
Modeling Ragged Hierarchies (Level)
Assuming the simple case described above (i.e. few number of edge case nodes, infrequent hierarchy changes), ragged hierarchies can be accommodated in 3 ways, depending on business requirements:
- Adding NULL or a PLACEHOLDER value at the missing level,
- Extending the parent node (or nearest ancestor node, more precisely) down to this level (this is the most common approach),
- Or extending the child node (or nearest descendant node) up to this level.

A final point worth considering is that it’s technically possible to have a hierarchy that is both unbalanced and ragged. I’ve never seen such a situation in real-life, so I’ll leave such an example as an exercise to the reader. Nonetheless, resolving such an example can still be achieved with the approaches above.
Versioning Hierarchies
As mentioned above, real-life circumstances could require a data model that accommodates multiple level attributes (i.e. in the case of ragged hierachies, or in the case of unbalanced hierarchies that should be transformed to ragged hierarchies for business purposes). There are different ways to do so.
- We could modify our hierarchy model with additional LEVEL columns. This approach is likely to be both brittle (by being tightly coupled to data that could change) and confusing (by modifying a data-agnostic model to accommodate specific edge cases). This approach is thus generally not recommended.
- A single additional semi-structured column, i.e. of JSON or similar type, would more flexibly accommodate multiple column levels but can introduce data quality / integrity concerns.
(At the risk of making this discussion more confusing that it perhaps already is, I did want to note that there could be other reasons (beyond the need for additional level attributes) to maintain multiple versions of the same hierarchy, which further motivate the two modeling approaches below. For example, in an org chart for a large consulting company, it’s very common for consultants to have a line (reporting) manager, but also a mentor, and then also project managers. So depending on context, the org chart might slightly different in terms of individual parent/child relationships, which often is considered a different version of the same overarching hierarchy.)
- Slowly-changing dimensions (hierarchies) – Using the org chart example, it’s clearly possible that an Executive Assistant to a CEO of a Fortune 100 company is likely higher on an org chart than an Executive Assistant to the CEO of a startup. As such, it’s quite possible that their respective level changes over time as the company grows, which can be captured as a slowly changing dimension, i.e. type 2 (or apparently type 7 as Wikipedia formally classifies it).
- Keep in mind these changes could be to the hierarchy itself, the employee themselves, the role they’re playing at given points in time, and/or some instantiation of the relationship between any of these two (or other) entities. Org chart data models can clearly get quite complicated.
- Versioned dimensions – I don’t think “versioned dimensions” is a formal term in data engineering, but it’s helpful for me at least to conceptualize a scenario where different use cases leverage the exact same hierarchy with slight changes, i.e. one use case (such as payroll analytics) considering the ragged hierarchy version, whereas another use case (such as equity analytics) considering the unbalanced version. Such situations would warrant a versioning bridge table (between the hierarchy table and the HR master data / dimension table, for example) that consists of at least four (conceptual) columns: a foreign key point to the hierarchy table, a foreign key pointing to the dimension table, a version field (i.e. an incrementing integer value for each version), and the LEVEL field with its various values depending on version. (A text description of each version would clealy also be very helpful.)
- Keep in mind that such versioning could be accomplished by physically persisting only those nodes that have different versions, or physically persisting all nodes in the hierarchy.
- Performance plays a role in this decision, depending on how consumption queries are generated/constructed (and against what data volumes, with what compute/memory/etc.)
- Clarity also plays a role. If 80% of nodes can have multiple versions, for example, I would probably recommend completely persisting the entire hierarchy (i.e. all of the corresponding nodes) rather than just the nodes in question.
- Keep in mind that such versioning could be accomplished by physically persisting only those nodes that have different versions, or physically persisting all nodes in the hierarchy.
For the time being, I’ll hold off on providing actual SQL and data models for such data model extensions. I want to help bring awareness to readers on ways to extend/scale hierarchy data models and demonstrate where some of the complexities lie, but given how nuanced such cases can end up, I’d prefer to keep the discussion conceptual/logical and hold off on physical implementation (while encouraging readers to coordinate closely with their respective Data Architect when encountering such scenarios).
This particular omission notwithstanding, the next and final post will summarize these first five points and walk through the corresponding SQL (data models and transformation logic) to help readers put all of the concepts learned thus far into practice.
And for reference, here are links to all of the posts in this series (next up is the final post #6):
Nodes, Edges and Graphs: Providing Context for Hierarchies (1 of 6)
More Than Pipelines: DAGs as Precursors to Hierarchies (2 of 6)
Family Matters: Introducing Parent-Child Hierarchies (3 of 6)
Flat Out: Introducing Level Hierarchies (4 of 6)
Edge Cases: Handling Ragged and Unbalanced Hierarchies (5 of 6)
Tied With A Bow: Wrapping Up the Hierarchy Discussion (Part 6 of 6)