The SAP Sales & Service Cloud (still widely referred to by its old name ‘SAP Cloud for Customer’, aka C4C) is SAP’s flagship application for managing customer interaction. For many enterprises, this is their primary source system for sales and services analytics. The C4C platform comes with no less than two integrated analytics solutions. Sooner or later, most sales managers and service managers have analytics requirements that go beyond the capability of the on-board analytics solutions. This happens when C4C data needs to be combined with data from other sources, or when C4C data needs to be made available for 3rd party tools, such as for machine learning or forecasting purposes. As C4C is a ‘Software as a Service’ (SaaS) platform (well, most of the time, anyway), the only way to get data out is by using the C4C APIs.
C4C comes with plenty of APIs, but not all of them are suitable for extracting data into a data platform. Furthermore, it can be a real challenge to get this configured correctly, particularly when building enterprise-grade data pipelines that require robust delta extraction logic. In this article, I will explore how to use the OData protocol to extract data from SAP C4C (in full or delta loads) and load it into Snowflake using Matillion.
For more about using OData to get data out of SAP, see my fellow colleague Jan van Ansem’s blog here.
OData & C4C
An OData service is a web-based endpoint that exposes data in a standardized format, making it straightforward to consume by different applications. It uses a RESTful API and can be accessed using standard HTTP methods. SAP C4C uses the OData protocol to expose its data for consumption by external applications, ideal for integrating into an ELT (Extract, Load, Transform) pipeline.
Firstly, it is important to distinguish between the two different object types that exist in C4C, those being Data Sources and Collections.
- Data Sources are for connecting to and building reports on from within a BI tool as the OData API pre-aggregates data sent in its API responses. The OData API does not provide any server-side pagination capability for Data Sources and so these objects are not ideal for ELT data extraction. Note: client-side pagination is possible but not recommended, as outlined in the disadvantages section in this SAP help documentation Client-Side Pagination | SAP Help Portal.
- Collections are the underlying data objects holding master and transactional data which are joined together to create the reporting Data Sources. Collections do have server-side pagination which makes them suitable for ELT data extraction via the OData API.
As a result, I recommend using collections rather than data sources for ELT data extraction. If you need to replicate the data structures of standard data sources then you can do so by using the collections and applying data transformations in your data warehouse.
Connection Testing
I always like to start in Postman to ensure that the API endpoint can be connected to and is returning data as expected. I suggest reading my previous blog here to understand how I use Postman to test and debug the OData APIs.
Matillion with OData
Matillion is an enterprise-grade and cloud-native ELT tool that connects to hundreds of source systems and APIs and loads data into your cloud data warehouse of choice. Matillion provides an OData extractor component which does most of the heavy lifting for us such as formatting the API URL with parameters and filters, as well as pagination logic.
Connecting in Matillion
In an OData component, add the base URL (i.e. up to but not beyond ‘…/c4codataapi’) to the ‘URL’ property in the OData component, as well as the basic authentication details (username and password). Note that we always recommend using a cloud key store integrated with Matillion to keep passwords securely. The URL format for the C4C OData service is as follows where the <myXXXXXX> is your C4C subdomain:
https://<myXXXXXX>.crm.ondemand.com/sap/c4c/odata/v1/c4codataapi/
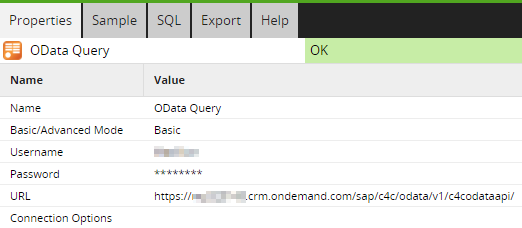
Next, we can select a Collection in the ‘Data Source’ property which will then allow you to choose from a list of fields in the ‘Data Selection’ property.

Select the fields you’d like to load and head to the ‘Sample’ tab where you should be able to pull back some data using the ‘Data’ button. You can also get a row count of the table which can be compared against a row count obtained in Postman, which I walk through in my previous blog here.
Filtering in Advanced Mode
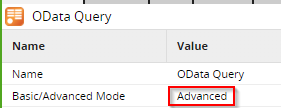
Next, we can set the ‘Basic/Advanced’ Mode property to ‘Advanced’ which lets us hand-write a SQL query which Matillion translates into an OData API request. This allows us to select specific fields and apply filters via a where clause.
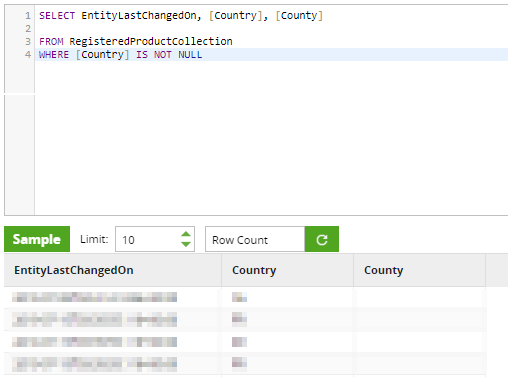
The ability to write our own where clause allows us to perform dela logic when loading incrementally from C4C using a timestamp filter. However, at Snap we’ve had an issue where the OData component could not correctly use a Snowflake timestamp to do delta loading from C4C. To overcome this issue, we’ve needed to add two Connection Options to the OData component:
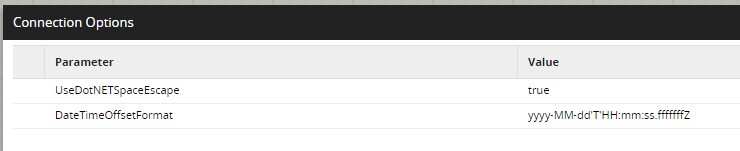
The first property will ensure that the component URL encodes spaces to %20 instead of + which is required by the OData API. The second property specifies the format for the timestamp that we will be passing into a where clause so that Matillion can understand it and use it correctly in the API call. Even though the DateTimeOffsetFormat is yyyy-MM-dd’T’hh:mm:ss.fffffffZ above, standard Snowflake timestamps can be passed in without needing to be modified e.g. WHERE “EntityLastChangedOn” > ‘2022-12-01 01:16:48.666’.
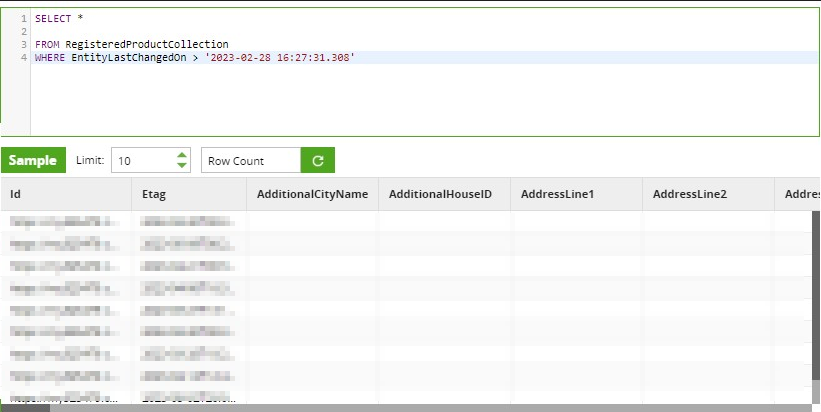
Once this is working correctly, this approach can be used to perform delta loads on tables to only load new or changed records, avoiding the need to load entire tables each time. This means your ELT pipelines can run faster and cheaper. I hope this article helps you with getting your data out of C4C. Please feel free to reach out to me on LinkedIn here if you have any further questions.