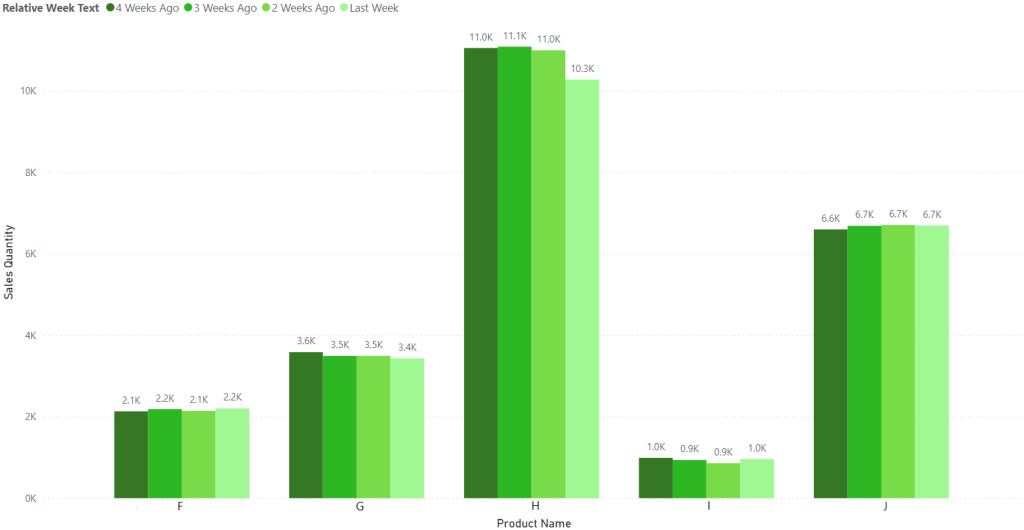
In Power BI, formatting colours for clustered bar charts can often feel like a repetitive, manual task – especially when using live date values as the legend. While applying a report theme can ensure consistency in colour schemes across the report, it also restricts flexibility, particularly when you want to introduce variation across different pages. In my case, I was dealing with weekly sales data where the financial week start date frequently changed, and updating the colours manually each week became too time-consuming. In this post, we explore how to automate dynamic colour formatting, enabling us to keep a cohesive look while effortlessly adapting to changing financial week data without manual updates.
Problem
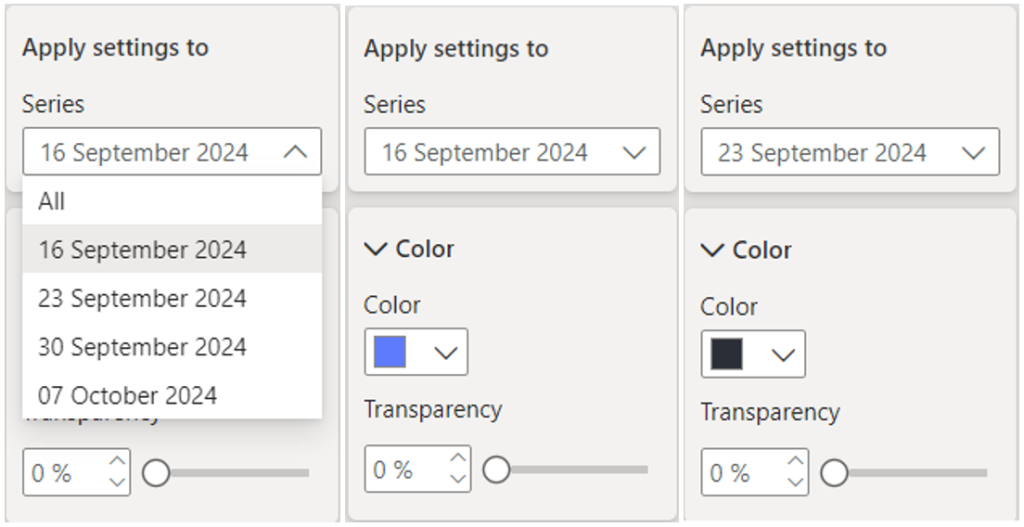
When using live and continuous date columns as the legend in a clustered bar chart, we can format individual elements, such as adjusting the colour of the bars or adding borders. However, any manually applied conditional formatting on the legend will revert to the default theme after each dataset refresh. This occurs because even minor changes in the data or shifts in the order of values cause Power BI to treat them as entirely new, thus forgetting the previous formatting.
Solution
One solution for this issue is to use a cyclical date column, such as the calendar month number. However, with this approach, we would still need to re-format the visual each month for an entire year until we return to the starting values. While this method works, repeating the process monthly becomes tedious and time-consuming.
Instead, a preferable solution is one that only needs to be implemented once and remains valid. To achieve this, we can use a “relative week” column in the date dimension, which calculates how far ahead or behind each date is from the current date. This ensures that legend values remain consistent, even after data refreshes.
Methodology
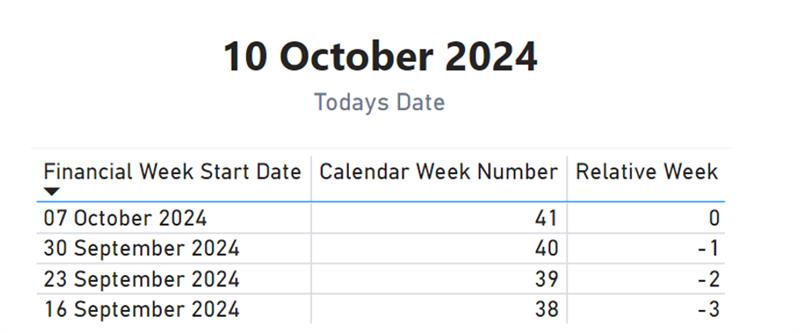
The “relative week” column is a calculated field that evaluates each date in the table and returns how many weeks ago or ahead that date is from today. The result is stored as a whole number, with positive numbers representing future weeks and negative numbers indicating past weeks. This simple but effective approach enables us to track relative time periods consistently across reports.
Here is the SQL logic we use to translate the numerical relative week values into more meaningful text:
CASE
WHEN RELATIVE_WEEK > 1 THEN (‘In ‘ || RELATIVE_WEEK::VARCHAR || ‘ Weeks’)
WHEN RELATIVE_WEEK = 1 THEN ‘Next Week’
WHEN RELATIVE_WEEK = 0 THEN ‘This Week’
WHEN RELATIVE_WEEK = -1 THEN ‘Last Week’
ELSE (-RELATIVE_WEEK::VARCHAR || ‘ Weeks Ago’)
END
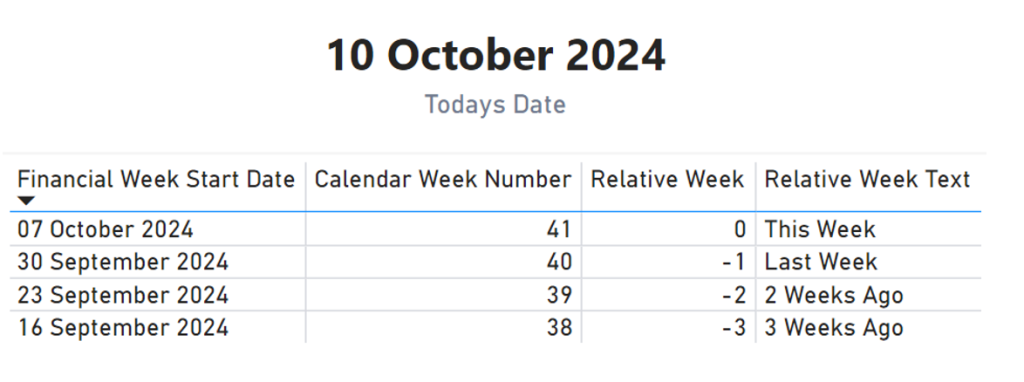
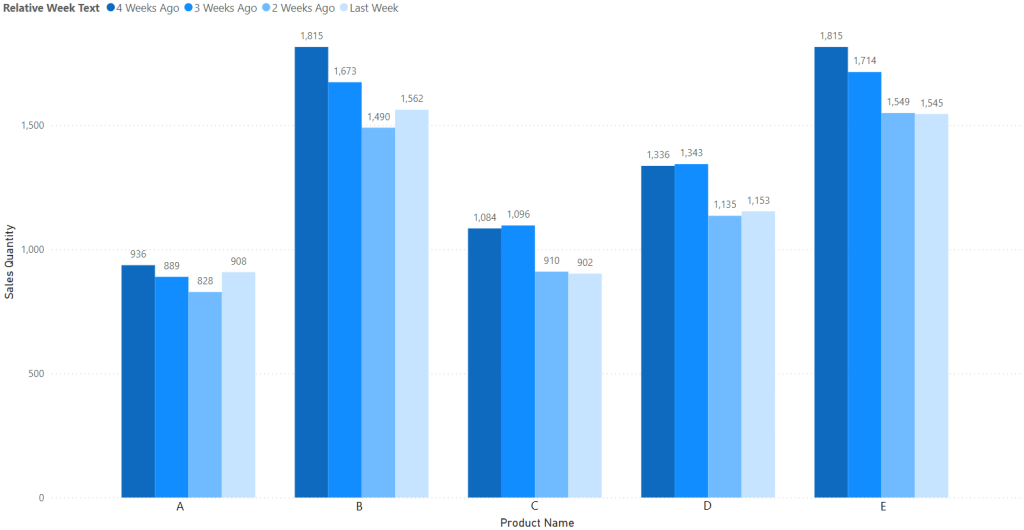
This SQL logic converts the relative week values into intuitive text, such as “Last Week” or “3 Weeks Ago”. By using text-based legend entries, Power BI treats the values as consistent across dataset refreshes, preventing the formatting from resetting.
Conclusion
By converting relative week values into text, we can ensure that our legend remains consistent after each refresh, preserving our conditional formatting without manual intervention. This simple automation technique streamlines the reporting process and guarantees a stable, dynamic visual experience in Power BI.
I encourage you to try this method in your own reports and see how it improves your workflow!
“Seeing is believing” is an expression used to emphasise that people are more likely to believe something when they see it with their own eyes. This expression can be applied to various situations, but I will apply this expression to the representation of Women in STEM.
“I wish I had more awareness of my female predecessors prior to entering college. I stumbled into this field.”
Shannon Loftis, Former VP of Microsoft Xbox Games Studios
We’re fortunate to live in a time where events like Women In Technology, Women in Data and Women of Silicon Roundabout serve as significant platforms for women in the technology sector to share their insights. These events, accessible both online and in-person, attract attendees from diverse backgrounds, countries, ethnicities, and expertise levels. I recently attended Big Data London, where I had the opportunity to connect with women from diverse backgrounds, each at different stages in their tech careers. Engaging with so many talented women and participating in diversity and inclusion seminars was an eye-opener—it made me realise that there are far more of us in the field than I had initially imagined. Events like Data Science Festival and Big Data London not only foster a sense of community but also offer students and recent graduates’ invaluable insights and guidance from experienced professionals. Seeing others who resemble themselves and have encountered similar challenges helps boost their confidence and in other cases alleviate impostor syndrome. Drawing inspiration from their stories empowers women to assert themselves and pave the way for future generations.
“I am so proud to see Minecraft: Education Edition engaging both boys and girls and teaching STEM subjects like coding and Chemistry in a wildly different way than they’ve been taught in the past 25 years.”
Deirdre Quarnstrom, VP of Microsoft Education
Notions suggesting that girls are less intelligent than boys or that it’s uncommon for girls to pursue STEM subjects have long persisted. From primary school through to university, some girls have grappled with the notion of being an outlier in their classes. While there has been notable improvement in gender balance, disparities still exist. However, the efforts of organizations like Girls Who Code, aimed at narrowing the gender gap by empowering girls to defy stereotypes, are significant. Guided by values of Bravery, Sisterhood, and Activism, they’ve garnered 14.6 billion engagements globally. Their initiatives, including summer immersion programmes, in-person classes, and clubs, have spurred 580,000 girls, women, and non-binary individuals to embark on their coding journeys, with 50% coming from underrepresented groups. This year, a dedicated group from Snap Analytics took on the Three Peaks Challenge, raising funds to support Hayesfield Girls’ School in upgrading their IT suite. Looking ahead, Snap plans to engage further by hosting sessions with the students, aiming to inspire and encourage them to explore careers in STEM. These sessions will also provide valuable insights into what it’s like to be a woman in tech, empowering the next generation of female leaders in the industry.
“Young girls are digital natives with the creativity and confidence to use STEM to drive positive change, yet we are failing to keep them engaged and excited about the possibilities.”
Mary Snapp, Vice President of Strategic Initiatives at Microsoft Corporate External & Legal Affairs
In 2019, the UK Department of Education reported a 25% increase in the number of women accepted onto full-time STEM undergraduate courses since 2010, with women constituting 54% of UK STEM postgraduates (Department of Education, 2019). Despite this progress, women continue to face challenges in applying for and securing STEM-related jobs. Research indicates that women occupy only 22% of all tech roles across European companies. Furthermore, a 2022 analysis by McKinsey revealed a projected tech talent gap of 1.4 million to 3.9 million people by 2027 in 27 EU countries (McKinsey Digital, 2023). While Google achieved its Racial Equity Commitment of increasing leadership representation of Black+, Latinx+, and Native American+ employees by 30% (Blumberg et al., 2023), achieving fair representation in the tech industry remains a distant goal. Despite these advancements, there is still a considerable journey ahead to achieve equitable representation for women and underrepresented groups. Employee retention goes beyond financial compensation, company culture plays a major role in this. One of the females at Snap commented “At Snap I feel like I am making a difference and that I am part of a team. There is not one day where I feel like I don’t have people to go to when I am struggling, but more importantly there are always people to support you and cheer for you when you are succeeding. I am constantly learning by observing the people around me and they inspire me everyday.”
“I think we need to mentor young girls and women to help show them what they can achieve with technology – not just what technology is, but what they can create with technology.”
Bonnie Ross, Corporate Vice President at Microsoft, Head of 343 Industries, Halo
Starting from a young age, parents can enrol their children in clubs, similar to those offered by Girls Who Code, to cultivate an early interest in technology. Teachers play a crucial role by intentionally sparking young girls’ interest in subjects like maths, physics, and chemistry. Furthermore, encouraging collaboration between young boys and girls fosters a comfortable environment for future teamwork. As they progress to high school and university, attending events like Women In Technology and Women in Data offers opportunities to connect with peers and seek mentorship from experienced women. Mentorship experiences often inspire recipients to pay it forward, creating a cycle of support for future generations of women. The goal is to empower young women to envision themselves succeeding in the tech industry by interacting with those who are currently in those positions.
Blumberg, S., Krawina, M., Makela, E., & Soller, H. (2029, January 24). Women in tech: The best bet to solve Europe’s talent shortage. McKinsey Digital. Women in tech in Europe | McKinsey
Matillion Data Productivity Cloud (DPC) has been quick to integrate some great AI features. AI helps with accelerating data engineering processes and can automate tasks which previously required laborious human effort. One of the use cases where leveraging AI can be beneficial is in the enrichment of data with metadata. In this blog post, Erick Ferreira illustrates this by enriching the publicly available IMDb dataset (see reference below). The enrichment is done with Cortex, which is Snowflake’s managed AI and machine learning service, and Matillion’s DPC, for fast and reliable engineering of data pipelines.
About the IMDb Dataset
IMDb provides an online database containing information about films and other sorts of digital content, such as television shows, video games and streaming content. The database was launched 34 years ago as a fan-operated movie database and nowadays, it is owned and operated by IMDb.com, Inc, a subsidiary of Amazon. The non commercial datasets can be used free of charge for non-commercial purposes1).
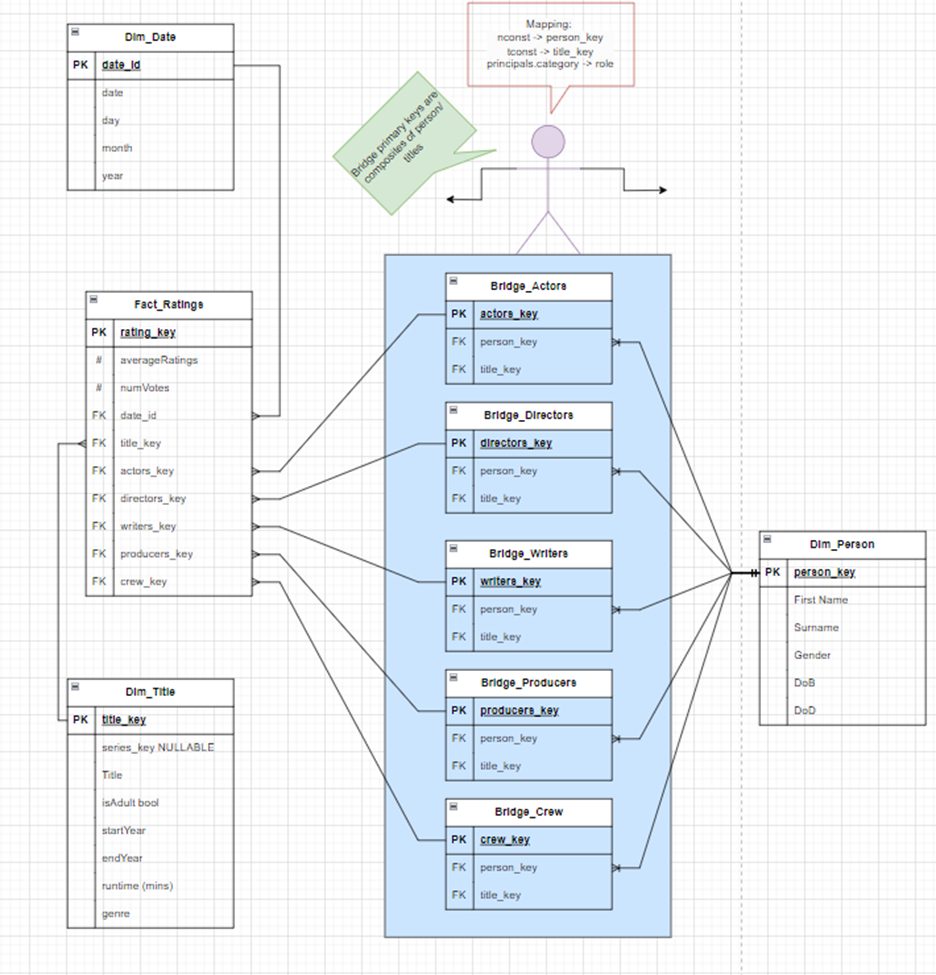
At Snap Analytics, we use the IMDb dataset for training purposes. Snap’s dimensional model (pictured on this page) for the IMDb database gives us a good starting point for metadata enrichment with AI. Here is the simplified model:
On top of this dimensional model, we added a reporting table with consolidated information about films, such as the name of the film, year of release, the director’s name, a summary of the film, duration, genre, etc…
IMDb data model
The challenge
We have the following two requirements for our use case:
We would like to know which film directos might have German ancestors. This information is not available in the metadata. We will use Cortex AI Completion to analyse the directors names, and add a column with an indication whether the name has a German origin or not.
For the Spanish speaking users, we would like to add a translation of the English film summary into Spanish. We will use Cortex Translate to automatically create this translation.
Below are the steps to achieve both requirements, by creating a DPC pipeline with some out of the box components.
Step 1: Create a Transformation Pipeline
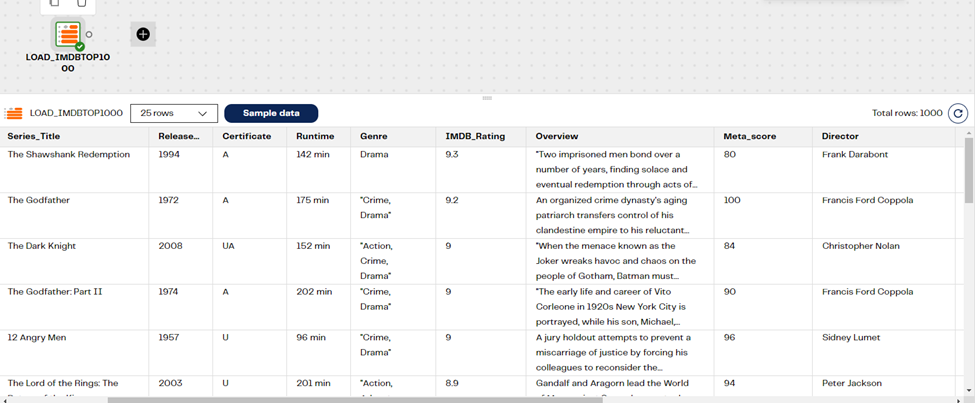
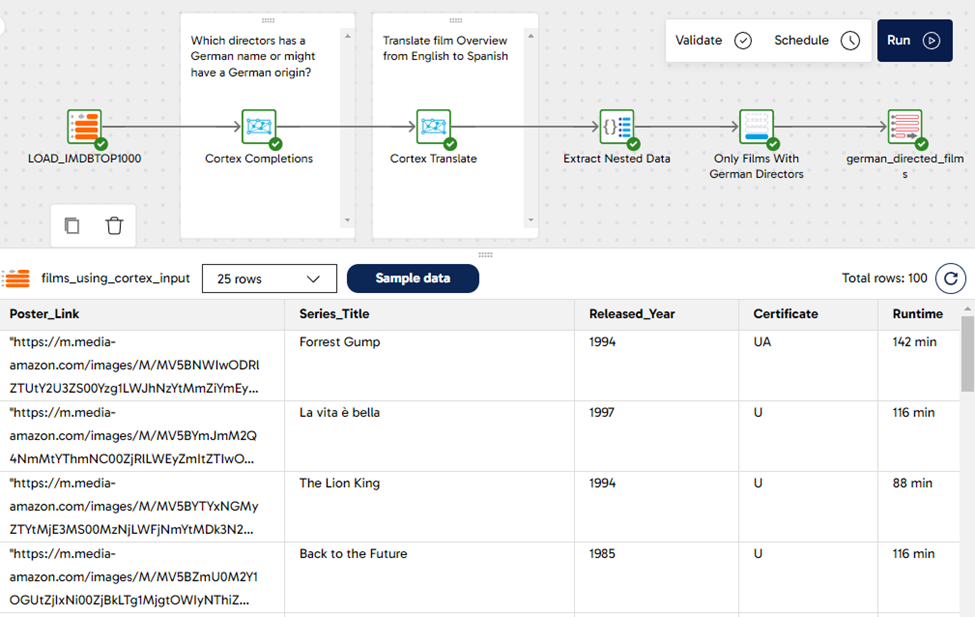
First, we created a Transformation pipeline with an Input Table component pointing to the IMDb reporting table, have a look at the screenshot below containing a sample of the data.
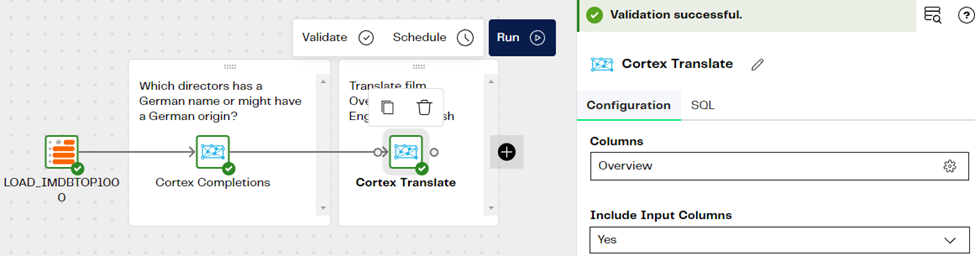
Step 2: Getting Directors with German Ancestors
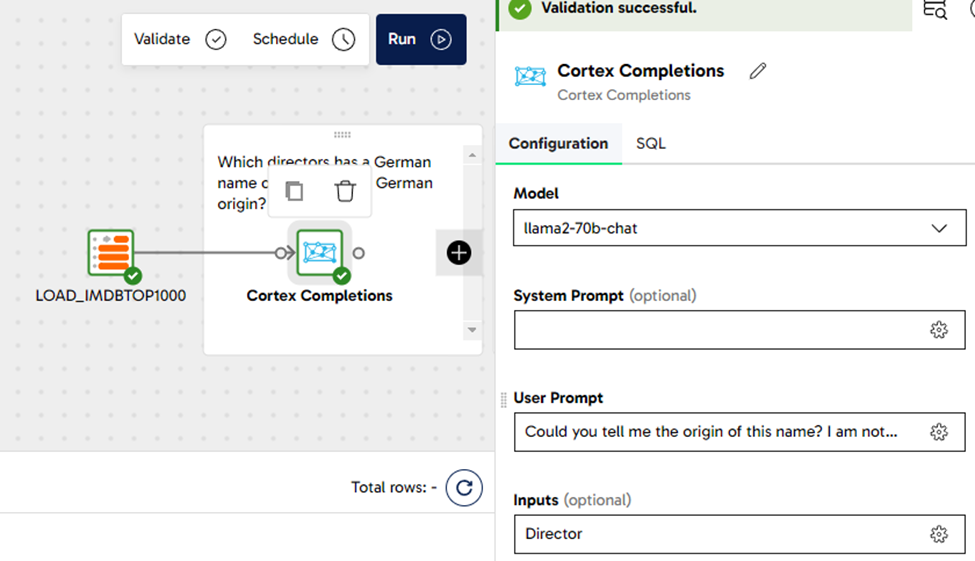
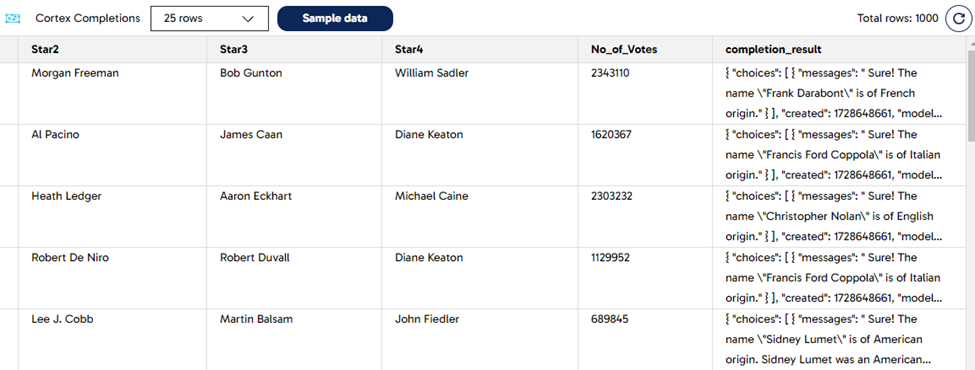
From the reporting table, we would like to recommend the films from German directors. We have used the Cortex Completions component using the Model llama-70b-chat with the following user prompt: Could you tell me the origin of this name? I am not interested in the nationality of the director; I would like to know the background of the name. We applied the question against the Director column. This will try to find all the surnames which have a German background. Look at the image below for some reference about the settings and how the pipeline looks like:
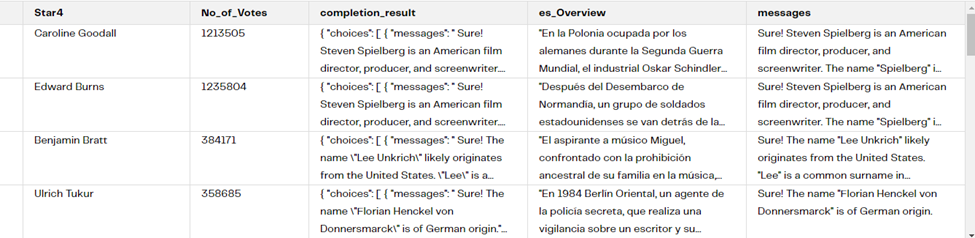
After doing a sample over the Cortex Completions component, we can see the “completion_result” column in JSON format with the answer in the “messages” attribute containing the origin of the director’s name.
This simple action of getting the background of a surname would have been a very laborious task without leveraging the use of Large Language Models (LLM). Moreover, it may require some extensive research, and potentially integrating with a third-party tool.
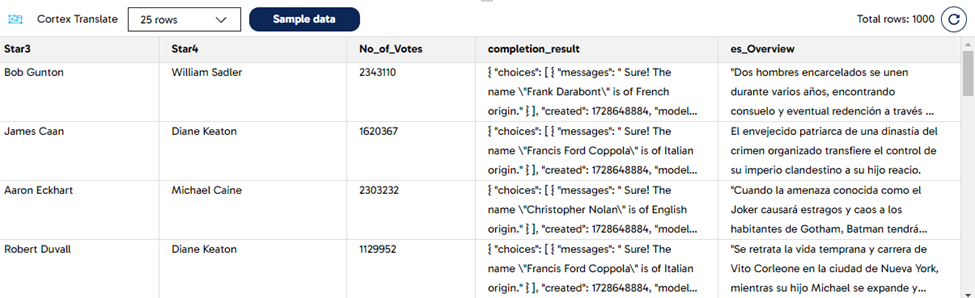
Step 3: Translate the Film Summary to Spanish
We use the Cortex Translate component in DPC to generate a Spanish translation. The “Overview” column contains the English original summary, which is used as input. Look at the example below for the settings and the outcome after sampling the data:
The Cortex Translate component will not only let you to translate from English to Spanish. There are several languages which you can select from the drop-down menu of the component. You can even have multiple columns as part of the output, one for each language that you need.
Step 4: Extract from semi-structured data
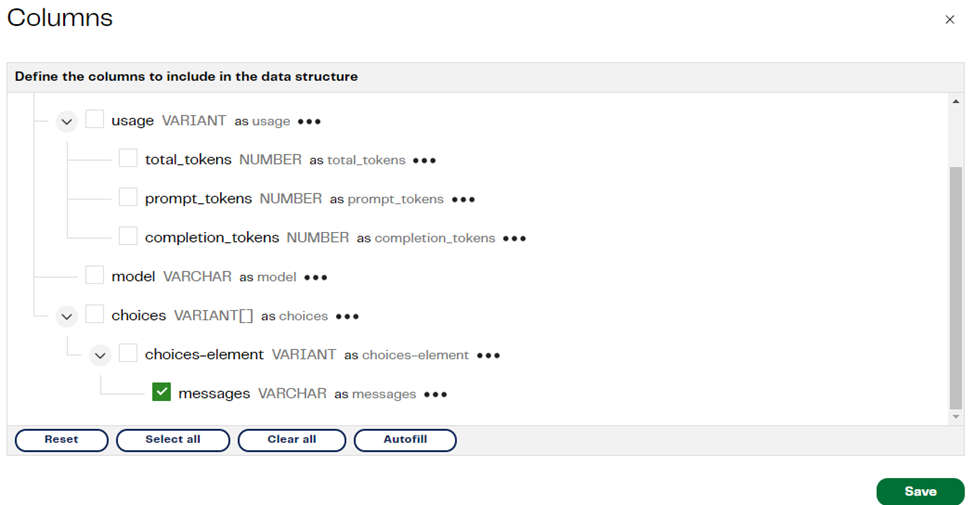
Now, as we are working in a Transformation pipeline and the outcome for the director’s surname is in JSON format, we can extract the “messages” attribute and then filter it out later in our pipeline. To do this, we can use the Extract Nested Data component. We will only check the messages field after autofilling the columns, this will allow us to get a new column with just the value for the “messages” attribute in plain text. Look at this below:
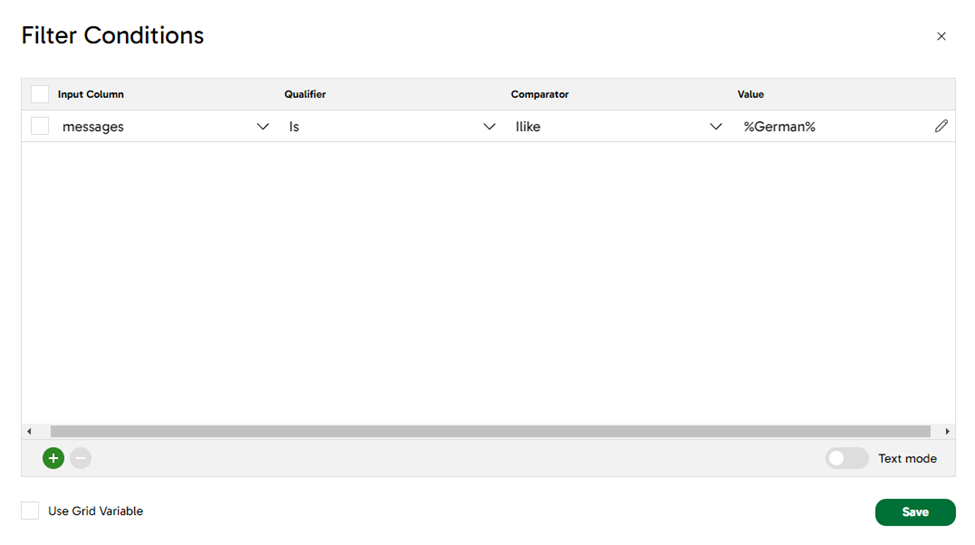
Step 5: Filtering the data
As we mentioned earlier, we want to only get the films for directors with German surnames, so we can use the Filter component to get only the rows where the text “Germany” or “German” appears. Check the filter condition property on the screenshot below:
This simple step will help us to remove all the rows in which the LLM did not identify a surname with a German background.
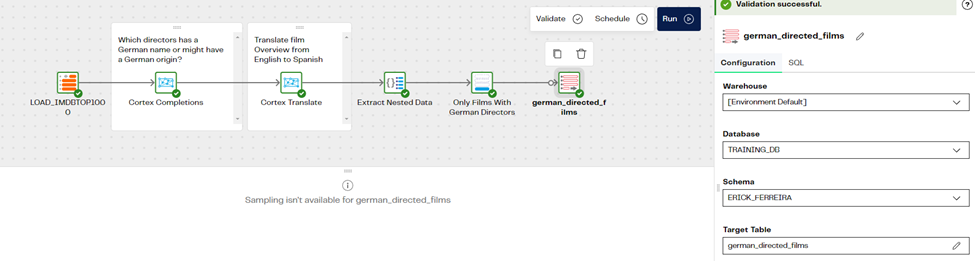
Step 6: Create a new table in Snowflake
Finally, we just must write the outcome of our pipeline into a table, we can use the Rewrite Table component to achieve this very easily. We will call our table “german_directed_films”. After running the pipeline, we should have a new table in Snowflake showing the specific outcome we built.
Step 7: The results
From the original reporting table containing 1,000 rows, we now have a smaller table containing only 100 rows. Each row represents a film with a director who has a German surname. Also, we have an extra column with the overview of the film in Spanish. Have a quick look at a sample of the data with the three new columns we created while building our pipeline:
Final thoughts
The new Snowflake Cortex is a game changer for analytics projects, it has the capacity to enhance metadata as we have demonstrated, and it is easy to see the value for more complex use cases, such as incorporating sentiment analysis or performing in-depth document analysis to generate outcomes that can be joined with more traditional business metrics.
Even though DPC is a platform mainly built for data engineering, you can see how easy it is to leverage the new AI features offered by Snowflake with a full no-code approach. DPC also brings other out of the box Orchestration components that leverage Large Language Models that we are also planning to cover as part of the other posts, such as vector databases and embeddings.
If you are looking to build data pipelines quickly and combine your analytics project with new AI features, DPC is definitely a platform you should try out. Here at Snap Analytics, we can also support you with your data and AI projects, especially if you are already a Snowflake user!
References and footnotes
Footnote 1: The IMDb non-commercial datasets can be used free of charge within the restrictions as set out by the non-commercial licensing agreement and within the limitations specified by copyright / license. Please refere to this page for more information: IMDb (2024) IMDb Non-Commercial Datasets. Available at: https://developer.imdb.com/non-commercial-datasets/ (Accessed 16 September 2024)
Digital exclusion is a pressing concern. According to the UK Government in its report on the Data Skills Gap, between 2019 and 2022, approximately 46% of businesses struggled to recruit for roles that required basic data skills. Moreover, about 25% of businesses reported a lack of data skills in machine learning, 22% in programming, 23% in knowledge of emerging technologies and solutions, and 22% in advanced statistics within their sectors. It is estimated that by 2030, UK will face its largest skills gap in basic digital abilities. AI has gained significant popularity over time, however, without targeted action, the growing use of AI will widen the divide between marginalized communities and those who are digitally connected. While regulatory bodies will lead most of the targeted actions, data engineers can also contribute significantly by actioning small changes to ensure everyone has access to the benefits of the AI experience. In this article we will look at what ‘digital exclusion’ means, and how simple changes in data engineering practices can make a difference.
The integration of AI has emerged as a game-changer, enabling businesses to personalize strategies, optimize processes, and enhance customer experiences. AI-driven analytics has revolutionized how companies connect with their target audience. However, concerns remain regarding digital exclusion, which can present itself in the form of the digital divide or algorithmic bias. As data engineers, it’s essential to recognize these challenges and proactively address the risks, ensuring that AI’s transformative potential benefits all users equitably. Later, I’ll present 4 actions data engineers can employ to mitigate the impact of algorithmic bias to help bridge this digital divide.
Digital divide
The digital divide describes the gap between people who have easy access to computers, phones or the internet compared to those who do not. Factors such as access barriers therefore play a major role in the increase of the gap. Access barriers can be described as obstacles that prevent people from using or benefiting from technology. These can include high costs, lack of infrastructure, limited digital literacy, and restrictive policies that prevent access to devices, internet, and digital services. In 2023, the House of Lords Communication and Digital Committee highlighted that digital exclusion remains a critical issue, with basic digital skills projected to be the UK’s most significant skills gap by 2030. The committee noted that the cost-of-living crisis has worsened the situation, making it even harder for people to afford internet access (Tudor, 2024(1)).
Algorithmic biases
Algorithmic bias refers to the discriminatory treatment which may stem from biases embedded within algorithms. As a result, disadvantages or advantages may be offered to certain groups of people. This bias appears in various forms, such as race, gender, ethnicity, age, or socioeconomic status. Furthermore, algorithmic biases can make unfair situations worse by leaving out some groups or reinforcing stereotypes as a result of skewed user demographics, leading to inaccurate consumer profiling and discriminatory targeting.
What you can do
Navigating these challenges requires proactive measures to mitigate biases. Data engineers can carefully scrutinize AI algorithms and implement transparent data practices. These include employing bias detection and mitigation algorithms, ensuring diverse and inclusive data collection and model development processes, and enhancing transparency and accountability in AI development and deployment. Scoring datasets is one method that can be used to achieve this. When it comes to scoring datasets on diversity properties, the goal is to assess how diverse the data is in terms of representation across different demographic groups or attributes. 4 key actions to follow to score these datasets include:
Quantifying diversity – This could involve calculating representation percentages.
Set thresholds or Benchmarks – Base these on organisational goals, industry standards, or regulatory requirements.
Score Diversity – For example, a dataset with balanced representation across different demographic groups would receive a higher diversity score.
Alternatively, data engineers can conduct representation analysis paired with the fairness analysis to assess if different demographic groups are represented equally in both the data and the outcomes produced by the algorithm. Initially a baseline comparison of the data using preferred demographics can be conducted. Following this, a fairness metrics such as demographic parity, equal opportunity, and disparate impact to evaluate how the algorithm treats different groups can be assessed. From the results the appropriate adjustments can be made to ensure greater representation.
Snap Analytics have progressed from a start up to a scale up. While diversity is a priority, formal measurement of diversity have only recently been implemented. By leveraging HR platforms and applicant tracking systems, valuable insights are being gathered. Snap’s approach includes 2 of the 4 key steps: (1) Defining diversity metrics and (3) Setting thresholds or benchmarks. Gender has been identified as the key diversity dimension, with the organization striving towards a 50/50 gender balance. However, as the company grows, they plan to expand the range of diversity metrics. Currently, diversity is measured through the following methods:
Diversity of candidates applying for roles at Snap.
Diversity within the organisation, across the different levels.
Job Satisfaction.
Employee retention.
Employee engagement.
When someone leaves, an exit interview is conducted with a follow up survey focusing on inclusivity, culture and diversity.
Businesses must prioritize diverse and representative datasets to mitigate inherent biases and provide users with the best experience possible. Additional ways to mitigate digital exclusion include implementing rigorous testing, and validation procedures can help identify and rectify any biases present in AI algorithms. Training and monitoring on ethical awareness among team members is also considered crucial, ensuring responsible deployment of AI technologies. Furthermore, ongoing monitoring and adjustment of AI systems are essential to address emerging biases and uphold ethical standards.
Policy makers have recently presented the EU AI Act which outlines regulations that ensure ethical AI usage, protect consumer privacy, and promote transparency. However, the gap between well connected and poor connected will not close if we leave it to government legislation alone. Socially responsible enterprises must develop and demonstrate plans to reach marginalized communities, using algorithms and datasets that avoid favouring majority groups. Data engineers can take the initiative by employing diversity metrics or representation analysis paired with the fairness analysis to identify unequal outcomes across different groups.
GOV.UK. (2021, May 18). Quantifying the UK Data Skills Gap – Full report. Quantifying the UK Data Skills Gap – Full report – GOV.UK (www.gov.uk)
We use cookies to ensure that we give you the best experience on our website. If you continue to use this site we will assume that you are happy with it.