What is Data Vault?
Firstly, what is Data Vault? Well, put simply it’s a modern approach to designing and building enterprise data warehouses. Most traditional data warehouses are designed and built using concepts from Kimball’s dimensional modelling and Inmon’s relational 3NF approaches. Data Vault combines the best bits from both star schema and 3NF approaches to design a more agile approach to building data warehouses which are designed for change, whilst also being scalable and able to handle petabytes of data. The data vault layer is introduced between staging and the dimensional star schema to track history and provide full traceability of the data.
Why is it needed?
While both Kimball’s dimensional modelling and Inmon’s relational 3NF were revolutionary when they were first introduced, the data landscape has changed significantly since the 1990’s. Nowadays companies capture a much greater variety of data rather than they did previously (which was mainly just transactional systems) such as semi-structured data, web data and machine generated data. The rate at which this data is being produced is increasing exponentially with 90% of the data on the web being created in the last two years alone according to a marketing cloud study conducted by IBM. Put simply, data warehouses that are built using these traditional methodologies are not responsive enough to the change that organisations are currently experiencing – which is where Data Vault comes in!
How does it work?
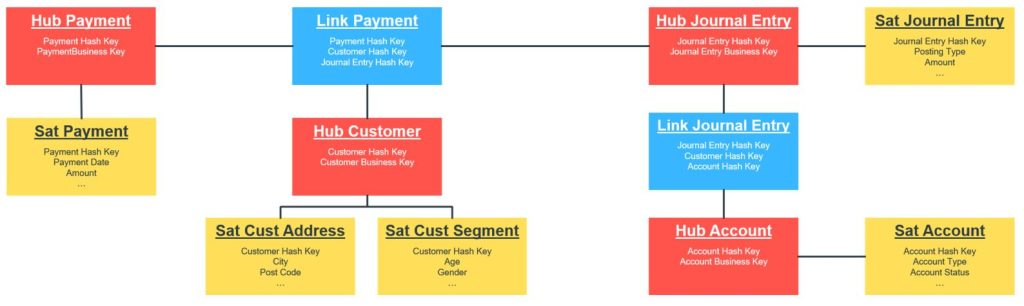
The Data Vault layer is based on patterns from nature using a hub-and-spoke architecture that scales well and is easy to extend. There are three distinct components to the data vault which are hubs, links and satellites.
Hubs
As the business keys tend to change less frequently than other data, these are separated into hubs which purely store the business key and the hashed key which is used to increase the loading performance of the data vault layer. In the example above, there are hubs for Customer, Account and Payment which represent the core business keys.
Links
There are then link tables which connect these hub keys together and represent the source business processes and transactions. The link tables are key in being able to improve the flexibility of the data vault model because it is easy to add new links, or to change the relationship of the links that are already in place. In the example above, the payment link table connects the Customer and the Payment hubs.
Satellites
Lastly, there are satellite tables which provide the additional data that adds context to a relationship or transaction. Most important, this is where the changes are tracked over time to enable the full history to be analysed. A single hub, for example Customer, may have several different satellites depending on the source system that provides those additional details or the rate of change for those particular fields. In our example above it is separate systems that provide the Address and Segmentation details which is why these are separated. This is also important as the changes for these particular fields from these systems can then easily be updated into the separate satellite tables that are affected.
Now you know a bit more about what Data Vault is, look out for part 2 of our Data Vault blog where we’ll highlight the key benefits of Data Vault methodology.
Written by Tom Bruce the Delivery Lead and Co-founder of Snap Analytics.